GPT-5.5가 2026년 4월 23일 출시되면서 OpenAI의 모델 정체성이 “대화”에서 “에이전트 런타임”으로 옮겨갔어요. 비전공자분이 알아야 할 5가지 핵심 변화, 코딩 벤치 점수의 의미, ChatGPT 사용자가 무리 없이 적응하는 5단계, Cursor·Copilot에서 5.5를 활용하는 법까지 출시 6일 차 시점의 정보로 정리했습니다. 지금 모델을 바꿔야 할지 망설이는 분께도 결정 기준을 함께 담았어요.
📑 목차
🎯 GPT-5.5 출시가 비전공자에게 중요한 이유
GPT-5.5가 2026년 4월 23일 정식 공개되면서 단순한 버전 업그레이드 이상의 변화가 있었어요. 핵심을 한 줄로 줄이면 “OpenAI가 처음부터 에이전트 런타임으로 설계한 첫 모델“이라는 점입니다. 이전 버전들은 본질적으로 대화·답변에 강한 모델이었고, 도구 사용은 위에 얹는 기능이었어요. 5.5는 도구 호출과 다단계 작업을 전제로 만든 모델이라고 보시면 됩니다.
비전공자분에게는 두 가지 의미가 있어요. 첫째, ChatGPT를 평소 쓰시던 분이라면 “질문하고 답변 받는” 도구에서 “일을 통째로 맡기는” 도구로 사용 습관이 자연스럽게 옮겨갈 수 있는 시기입니다. 둘째, Cursor·GitHub Copilot 안에서도 GPT-5.5를 모델로 선택할 수 있게 되면서 본인이 직접 OpenAI를 쓰지 않으셔도 영향이 옵니다.
경험상 새 메이저 모델이 나오면 한국어로 정리된 글이 나오기까지 보통 2~3주가 걸려요. 그 사이에 변화 윤곽을 잡으시면 도구 선택과 워크플로 점검이 한층 수월해집니다. 이 글은 출시 6일 차 시점에 OpenAI 공식 발표와 NVIDIA·GitHub의 도입 자료를 정리한 자료라고 보시면 돼요.
📋 GPT-5 vs GPT-5.5 핵심 차이 한눈에
가장 빠르게 차이를 보시려면 표가 편해요. 본인이 자주 쓰는 항목부터 비교해보세요.
| 항목 | GPT-5 (이전) | GPT-5.5 (2026-04-23) |
|---|---|---|
| 모델 정체성 | 대화·답변 중심 챗봇 | 에이전트 런타임 (도구 사용 전제) |
| 작업 단위 | 질문 1개 ↔ 답변 1개 | 여러 단계·여러 도구 묶음 자동 실행 |
| 도구 사용 | 플러그인·코드 인터프리터 등 부분 지원 | 브라우저·코드·문서·스프레드시트 통합 |
| 코딩 성능 | SWE-Bench Pro 약 50%대 | SWE-Bench Pro 58.6%, Terminal-Bench 2.0 82.7% |
| API 위치 | 일반 모델 패밀리 | Codex·NVIDIA 인프라에 즉시 결합 |

표만 봐서는 변화의 폭이 잘 안 와닿을 수 있어요. 다음부터는 5가지 변화를 하나씩 풀어드릴게요. 각 변화마다 비전공자분이 어떻게 활용하면 좋을지도 함께 적었습니다.
🚀 변화 1 — 에이전트 런타임 우선
GPT-5.5에서 가장 큰 변화는 모델의 기본 자세예요. 이전에는 “질문이 들어오면 답한다”가 기본 자세였습니다. 5.5는 “일이 들어오면 끝까지 한다”가 기본이에요. OpenAI 공식 발표에서도 “agent runtime”이라는 표현을 정면에 내세웠습니다. 단순 표현 변경이 아니라 학습 단계부터 도구 호출·다단계 추론을 가정하고 만들어졌다는 뜻이에요.
본인이 할 일은 일을 자연어로 위임하는 것입니다. “이번 주 매출 데이터 정리해서 차트 만들고 보고서 1쪽으로 요약해줘”라고 시키면 모델이 데이터 도구를 열고, 분석하고, 차트를 그리고, 문서까지 만들어요. 본인은 결과만 보시면 됩니다.
비전공자분에게 의미가 큰 이유는 명확해요. 기존 GPT-5는 본인이 단계마다 다음 지시를 내려야 했어요. 5.5는 한 문장 위임으로 끝까지 가는 횟수가 늘어납니다. 코드를 못 읽으셔도 결과물 화면만 보고 판단하는 일은 누구나 할 수 있거든요.
처음 5.5를 켜시면 “이게 뭐가 다르지?” 싶을 수 있어요. 평소처럼 짧은 질문만 하시면 차이가 잘 안 보이거든요. 대신 “이번 주 받은 메일 중 답변 안 한 것만 정리해서 표로 만들어줘”처럼 여러 단계가 묶인 일을 한 번에 시켜보세요. 차이가 즉시 체감됩니다.
🔄 변화 2 — 도구 묶음 자동 실행
두 번째 변화는 도구를 넘나드는 능력이에요. 5.5는 한 번의 위임 안에서 브라우저·코드·문서·스프레드시트를 자유롭게 오갑니다. 이전에는 “브라우징은 이 메뉴, 코드는 저 메뉴”처럼 본인이 도구를 골라줘야 했고, 도중에 끊기는 일도 잦았어요. 5.5는 그런 끊김이 줄었다고 보시면 됩니다.
예를 들어 “오늘 IT 뉴스에서 GPT-5.5 관련 기사 5개 찾아서 핵심만 요약하고 표로 정리한 다음 한국어 트윗용 한 줄 요약까지 뽑아줘”를 시키시면 다음 작업이 한 호출 안에서 묶여요. 브라우저로 검색 → 본문 추출 → 요약 → 표 작성 → 한국어 번역 → 트윗 길이로 압축. 사람이 중간에 개입할 일이 거의 없습니다.

비전공자분이 이걸 잘 쓰려면 일을 묶어서 던지는 습관이 필요해요. “검색해줘 → 정리해줘 → 번역해줘”처럼 단계별로 끊지 마시고, 처음부터 결과물 형태까지 한 번에 적어주세요. “표 / 요약 / 트윗 1줄”처럼 본인이 원하는 산출물을 명확히 적으시면 모델이 거기에 맞춰 도구를 골라 씁니다. 첫 며칠은 어색해도 일주일이면 감이 와요.
📈 변화 3 — 코딩 벤치 약진과 의미
세 번째 변화는 코딩 능력의 도약이에요. 공식 수치로 보면 Terminal-Bench 2.0에서 82.7%, 실 GitHub 이슈를 다루는 SWE-Bench Pro에서 58.6%를 기록했습니다. 이전 GPT-5의 같은 벤치 점수와 비교하면 한 단계 위로 올라간 수치예요. 다만 같은 시점 Claude Opus 4.7의 SWE-Bench Verified가 87.6%를 기록한 만큼 “절대 1등”은 아닙니다.
비전공자분에게 이 숫자가 의미 있는 이유는 두 가지예요. 첫째, 본인이 ChatGPT 안에서 코딩 도움을 받으실 때 결과 품질이 높아집니다. 둘째, GitHub Copilot·Codex가 GPT-5.5를 사용하기 시작하면서 본인이 직접 모델을 의식하지 않아도 코딩 도구의 결과가 좋아져요. 즉 OpenAI 모델을 직접 쓰지 않으셔도 효과가 옵니다.
# GPT-5.5에 코드 위임할 때 효과적인 프롬프트 예시
# (ChatGPT나 OpenAI API 둘 다 동일)
"Next.js 14 앱에서 회원가입 폼을 만들어줘.
- 이메일/비밀번호 두 필드
- 클라이언트 측 유효성 검사 (이메일 형식, 비밀번호 8자 이상)
- 제출 시 /api/signup으로 POST
- 성공/실패 메시지 표시
- Tailwind CSS로 깔끔하게
결과물은 단일 React 컴포넌트 파일 하나로 줘."
# 5.5는 한 호출 안에서 폼 / 검사 / API 호출 / 에러 처리까지 묶어서 반환실수 패턴 한 가지만 짚어드릴게요. 5.5라고 해서 모호한 지시(“좋게 만들어줘”)의 결과 품질이 자동으로 좋아지진 않아요. 본인이 원하는 산출물 형식·기술 스택·제약 조건을 1~3줄로 적어주시면 결과 품질이 눈에 띄게 올라갑니다. 모델이 강해질수록 본인 지시가 명확할수록 효과가 커진다고 보시면 돼요.
🧩 변화 4 — 슈퍼앱으로의 진화
네 번째 변화는 모델 하나가 다루는 일의 범위예요. 코드만 짜는 모델이 아니라, 자료 조사·데이터 분석·문서 작성·소프트웨어 조작까지 한 모델 안에서 처리합니다. OpenAI 본인들도 “ChatGPT를 슈퍼앱으로 끌고 가는 모델”이라는 표현을 썼어요. 풀어 말하면 “여러 앱을 따로 쓸 일이 줄어든다”입니다.
비전공자분에게 가장 체감되는 부분은 일감의 입구가 ChatGPT 하나로 줄어든다는 점이에요. 예전에는 검색은 구글, 분석은 엑셀, 글은 워드 식으로 앱을 옮겨다녀야 했어요. 5.5에서는 그 흐름을 한 창에서 끝낼 수 있는 비중이 커집니다. 본인이 마우스로 앱 사이를 옮겨다니는 시간이 자연스럽게 줄어드는 셈이에요.
“한 모델에 다 맡길 수 있다”가 “한 모델만 쓰면 된다”는 뜻은 아니에요. 본인이 데이터를 다루는 분이라면 여전히 엑셀이 빠르고, 글을 다듬는 작업은 별도 에디터가 편할 수 있습니다. 5.5는 “1차 자동화의 진입점”으로 쓰시고, 마무리는 익숙한 도구로 보내시는 분기가 현실적이에요.
⚙️ 변화 5 — Codex·Copilot 간접 효과
마지막 변화는 본인이 5.5를 직접 쓰지 않아도 영향이 온다는 점이에요. 출시 다음 날 OpenAI는 Codex API에 5.5를 즉시 적용했고, GitHub는 Copilot에 5.5 옵션을 순차 풀고 있습니다. NVIDIA는 GPT-5.5 인프라를 내부 코딩 에이전트에 도입한다는 발표를 함께 냈어요. 결과적으로 본인이 Cursor·Copilot·VS Code 어딘가에서 모델을 고를 때 “GPT-5.5″가 선택지에 들어오는 시기가 옵니다.
비전공자분 입장에서는 굳이 이름을 외우실 필요 없어요. 본인 도구의 모델 선택 메뉴에서 “최신 / Latest” 옵션을 고르시면 자동으로 따라 올라갑니다. 다만 본인이 어떤 모델을 쓰고 있는지 한 번 확인하시면 결과 품질 차이를 체감하시는 데 도움이 돼요.
# Cursor에서 모델 변경 (Cursor Settings → Models)
# Claude Opus 4.7 ← 코드 깊이 작업에 강함
# GPT-5.5 ← 도구 묶음 자동화에 강함
# Gemini 3.1 Pro ← 긴 컨텍스트 분석에 강함
# 본인이 자주 쓰는 작업 유형에 맞춰 기본 모델 1개 + 보조 1개를 정해두시면 좋아요
# 예: 기본 = GPT-5.5, 보조 = Claude Opus 4.7두 번째 변화처럼 사소해 보일 수 있어요. 다만 본인이 매일 쓰는 도구 안에 더 강한 모델이 들어오는 셈이라 누적 효과가 큽니다. 한 달 단위로 본인 작업 시간이 의외로 줄어드는 걸 느끼시는 분들이 적지 않아요.
🛠 비전공자 적응 5단계
모든 변화를 한 번에 익히려 하지 마세요. 다음 5단계로 1주씩 차근차근 진행하시면 무리가 적습니다.
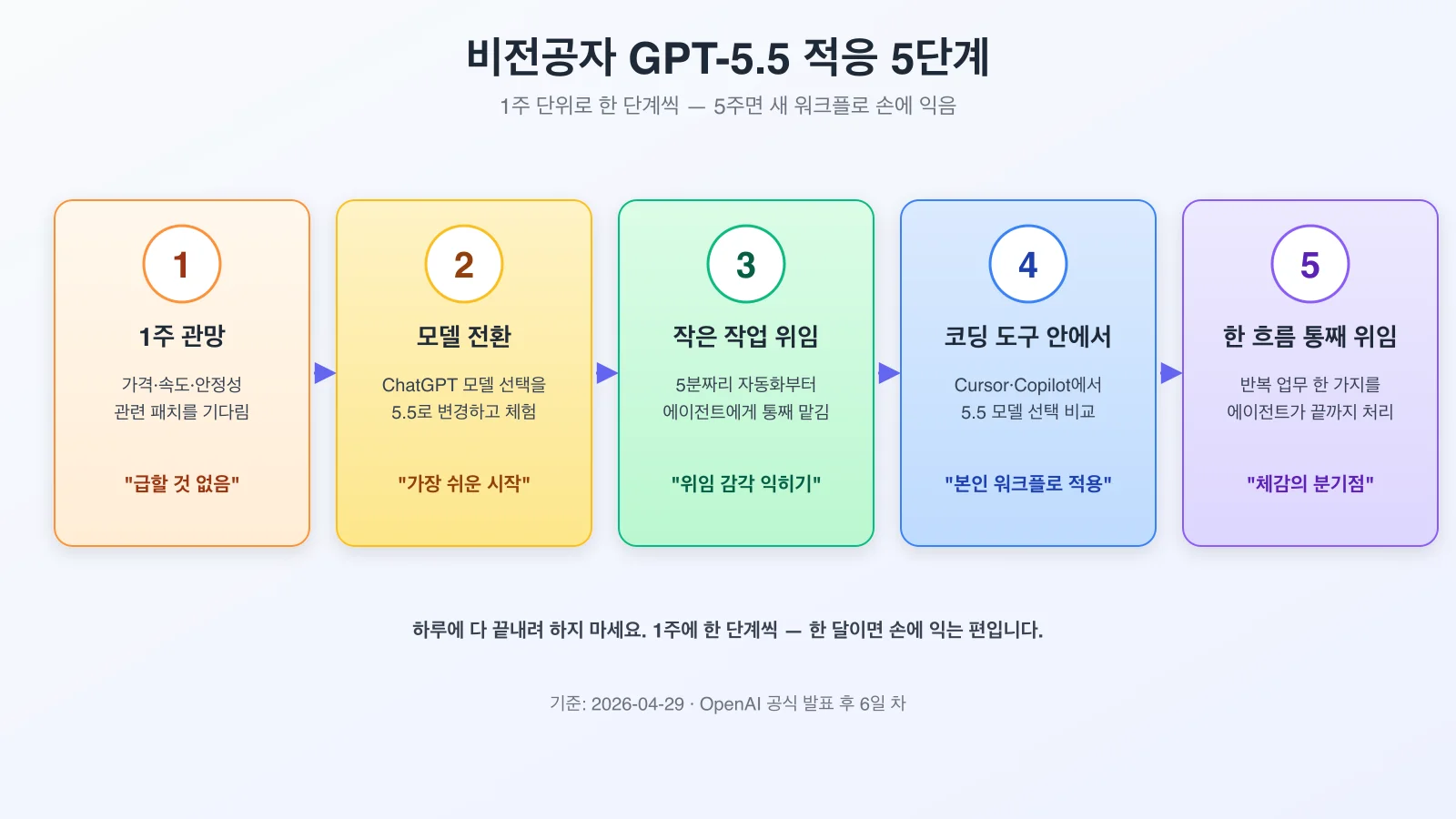
1단계 — 1주 관망
출시 첫 1주는 가격·속도·한도 정책이 자잘하게 조정돼요. 지금 바쁜 프로젝트가 있으시면 1주 정도 관망하시는 편이 안전합니다. openai.com/chatgpt/release-notes나 status.openai.com을 즐겨찾기 해두시면 변경 안내가 바로 보여요.
2단계 — ChatGPT 모델 전환
가장 쉬운 시작은 본인이 평소 쓰시는 ChatGPT의 모델 선택을 5.5로 바꾸는 거예요. 새 도구를 설치하실 필요 없고, 기존 대화 패턴 그대로 사용하시면서 차이를 자연스럽게 느끼실 수 있습니다. 본인이 무료 사용자라면 한도 안에서, Plus 사용자라면 더 넉넉한 한도로 쓰실 수 있어요.
3단계 — 작은 작업 위임
두 번째 주에는 5분짜리 자동화부터 위임 감각을 익혀보세요. “이메일 3개 작성해줘”, “이번 주 일정 표로 정리해줘” 같은 가벼운 일을 통째로 시키시면 됩니다. 단계별로 쪼개는 습관이 있으시다면 의도적으로 한 호출에 묶어보세요. 위임이 익숙해지는 게 5.5 활용의 분기점입니다.
4단계 — 코딩 도구 안에서 비교
세 번째 주부터는 Cursor·GitHub Copilot 같은 코딩 도구 안에서 5.5를 모델 선택지로 꺼내보세요. 같은 일감을 GPT-5.5와 Claude Opus 4.7로 한 번씩 시켜보시면 본인 워크플로에 어느 모델이 잘 맞는지 감이 잡힙니다. 본인이 직접 비교해보신 결과가 가장 정확해요.
5단계 — 한 흐름 통째 위임
네 번째 주에는 본인이 매주 반복하는 업무 한 가지를 통째로 위임해보세요. 주간 보고서 작성, 매출 정리, 메일 답장 초안 같은 일이 좋습니다. 첫 시도는 결과 검토에 시간이 걸리지만, 두 번째부터는 위임 → 검토 흐름이 자리 잡으면서 의외로 시간이 줄어요. 이 단계가 진짜 체감의 분기점입니다.
⚠️ 지금 모델을 바꿔도 될까
“바로 5.5로 갈아탈까, 좀 더 보고 결정할까” 망설이는 분이 적지 않으세요. 결정 기준을 한 줄씩 정리해드릴게요.
| 본인 상황 | 모델 전환 권장 |
|---|---|
| ChatGPT를 거의 안 써본 비전공자 | 지금 5.5로 시작 OK — 어차피 새로 배움 |
| 마감 임박 프로젝트에 GPT-5로 흐름이 잡혀 있음 | 마감 후 전환 — 산출물 형식 차이 가능 |
| 주로 ChatGPT에서 자료 조사·문서 작성 | 지금 전환 — 도구 묶음 효과 큼 |
| API로 자체 서비스 운영 중 (요금 민감) | 1~2주 관망 — 가격·한도 안정화 후 결정 |
| Cursor·Copilot에서 Claude로 만족 중 | 병행 비교만 권장 — 즉시 갈아탈 필요는 없음 |
어떤 모델을 코딩에 쓸지 고민된다면 AI 코딩 도구 비교 2026에서 도구별 기본 모델을 비교해 보세요.
같은 프롬프트라도 GPT-5와 5.5의 결과 형식이 살짝 다를 때가 있어요. 본인이 자동화 스크립트나 외부 시스템에 5의 출력 형식을 그대로 연결해두셨다면, 5.5로 전환 후 한 번 결과를 점검하시는 게 안전합니다. 형식 차이는 보통 프롬프트에 출력 예시 1개를 붙여주시면 해소돼요.
📋 면책조항
여기까지 잘 읽어주셔서 감사드려요. GPT-5.5는 “더 똑똑해진 ChatGPT” 한 줄로 줄이기 어려운 변화입니다. 모델 정체성 자체가 답변에서 위임으로 옮겨갔다고 보시면 돼요. 본인 페이스대로 1주에 한 단계씩 적용하시면 한 달 안에 손에 익는 편입니다.
❓ FAQ
질문을 누르면 답변이 펼쳐집니다.
🔰 처음 접하기 전 궁금한 것들
Q. GPT-5.5는 무료로 쓸 수 있나요?
Q. GPT-5와 비교해서 사용법이 완전히 달라졌나요?
Q. 한국어로도 잘 작동하나요?
Q. Claude Opus 4.7과 비교하면 어느 쪽이 낫나요?
🛠 실제 사용 중 자주 마주치는 상황
Q. 5.5에 위임했는데 중간에 멈추면 어떻게 하나요?
Q. 5.5의 결과 형식이 5와 미묘하게 달라요. 어떻게 맞추나요?
Q. 5.5가 인터넷을 직접 검색해서 잘못된 정보를 가져올 때가 있어요.
Q. ChatGPT에서 5.5로 코드를 작성받았는데 그대로 쓰면 되나요?
🚀 다음 단계로 확장하기
Q. 5.5를 Cursor에서 쓰려면 어떻게 해야 하나요?
Q. GitHub Copilot에서도 5.5가 자동으로 쓰이나요?
Q. API로 5.5를 호출할 때 비용은 어떻게 다른가요?
🔗 관련 글
- Cursor 3 출시 — 비전공자가 알아야 할 5가지 변화
- AI 코딩 도구 비교 2026 — Copilot vs Cursor vs Claude
- Cursor vs Claude Code — 비전공자에게 더 나은 선택은?
- 2026 AI 코딩 도구 트렌드 총정리 — 5월 업데이트
- AI 에이전트로 개발하기 — 바이브코딩의 다음 단계
📚 참고 자료
- Introducing GPT-5.5 — OpenAI 공식 발표
- OpenAI Codex GPT-5.5 on NVIDIA Infrastructure — NVIDIA 블로그
- OpenAI releases GPT-5.5 — TechCrunch
- GPT-5.5 — Wikipedia
IT 기획 10년차 / 비전공자를 위한 바이브코딩 블로그 운영 / vibe-start.com 제작
Building VibeStart — the fastest path for non-devs into AI coding. Launching on Product Hunt 2026-05-26.